Open Telemetry
Manual instrumentation of program using Opentelemetry and uses Jaegur for Tracing
Project maintained by Frimpong Clement Hosted on GitHub Pages — Theme by mattgraham
Return to Homepage
Benchmark Discussions
Opentelemetry & Tracing
The program has two main parts; the Client which employs a Sequential processing of task and the Server side which employs Parallelism processing:
- Client - Sequential: The client-side method that reads the files and send to the server does so in a sequential manner. Files are read individually, one after the other and once the reading is completed, the read data is converted to a list of strings and sent to the server and the next file is read. The whole process repeats until all files are read and sent to the server. It has two sequential parts, that is two for-loops.
- Server - Parallelism: The server-side method function upon receiving data from the client-side creates a thread to process the writing of the data into a local file. The number of distinct data received determines the number of threads to be created. In this case, 10 data are recieved hence ten threads and each thread is discarded after it is done process. All threads are join together to complete their processing before the application exits. Each thread created, processes its data exclusive of other threads. All threads access the same local file where they write into which could have led to a race condition.
Race Condition
Concurrent access to the same file during writing could cause a race condition where the value or content would be different anytime the program is run. Python 3 which was used here in the program handles well race condition instances without having to apply lock/release of a shared resource. In that case, no race conditions were observed here. By observing the output file size (8.1mb) after multiple separate runs, it was always equal to the total size of the 10 files combined (8.1mb) hence there was no loss or addition of data.
Instrumentation and Tracing
The invocation of any function was traced using Opentelemetry API and SDK. Manual instrumentation was done, and the trace data was exported to Jaeger for analysis. Jaeger was set up locally in a Docker container. The result is as show in the image below:
click on image to open fully
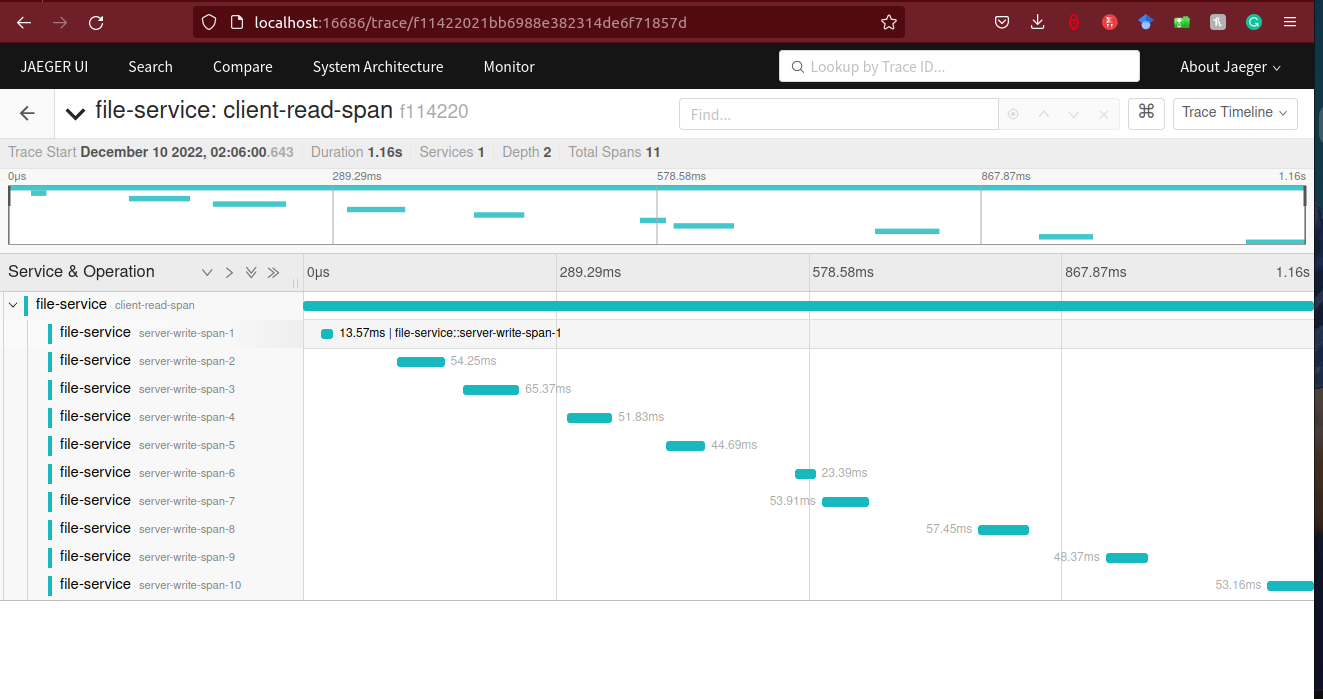
Results Analysis
From the results image above, the client-read-span is observed to have been called once which invoked the calling of the server-write-span 10 times. There were 11 spans in total hence but dept of trace was only two; first depth level being the client span and the 10 server spans have the same depth level.
It took 1.16s to complete the whole reading and writing processes. The write operations had varied execution durations due to a lot of execution environment’s factors such as the file size, number of lines in each file, waiting time for resource to be free for writing, etc. and external factors such as memory, cpu and cache.
Server Writing Timelines
From the timelines, none of the write spans intersected each other because the read operations were sequential hence no two data were received by the writer server at the same time during the execution period. And the writing operation of each thread was sequential(for-loop). Implementing threading for reading the files concurrently had a lot of overlapping write times. And the time intervals of one write span after the previous varied because the server received data from the client at different intervals.
Improvement in Speed of Program
Refactoring most task intensive parts of the program like reading files from disk to execute in parallel would have greatly reduced the total time for completion of reading and writing of files. This is because most of the operations would have been done concurrently but would have increased the likelihood of a race condition which would affect the final output file.
Log File - logs.txt
In the logs.txt file, it is observed from the Client logs that the client read and sent data to the server in an orderly manner: reading file 1, completed reading file 1; reading file 2, completed reading file 2. This means that a task needed to be operated before the next because the same thread was used for all tasks. But for the Server logs intercepted each other because each write task had a dedicated thread on which it executed.
Student Details
Name: Clement Frimpong Osei
Link to Repository: Assignment Repository